×
请登录
账号
密码
登录 Use it
博客
新媒体
活动
方案
爬虫
热点
标签
登录
注册
博主QQ
博主QQ:
博主微信
博主微信:
博主公号
博主公众号:
回到顶部
爬虫系列之基于XPosed框架的微信公众号采集
面试官:比如有10万个网站,有什么方法快速的取到数据吗?
爬虫系列之自动化运维(一)服务器节点详细设计
基于微信公众号平台的公众号、公众号文章、视频号等数据采集源码
# -*- coding: utf-8 -*- from selenium import webdriver import time import json import requests import re import random #微信公...
十点数据
博客
1年前
612
1
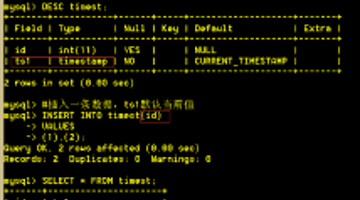
mysql获取当天,昨天,本周,本月,上周,上月的起始时间
今天 SELECT DATE_FORMAT(NOW(),'%Y-%m-%d 00:00:00') AS '今天开始'; SELECT DATE_FORMAT(NOW(),'%Y-%m-%d 23:59:59') AS '今天结束'; 昨天 SE...
十点数据
博客
1年前
488
0
python项目中,如何导出依赖的第三方库,并在新环境中安装
法一: 将会导出当前Python环境下所有类库包 1. 导出项目安装过的第三方库-激活项目环境,在终端命令行输入: pip freeze > requirements.txt 2. 在新环境安装已导出的第三方库: 命令行或终端输入: pi...
十点数据
博客
1年前
1051
0
解决requests下载网页时的"RecursionError: maximum recursion depth exceeded while calling a Python object"错误!
我的requests库是2.25.0,重新安装2.23.0解决问题。其他版本没有尝试,具体原因尚未详细研究。 pip install requests==2.23.0
十点数据
爬虫
1年前
683
0
Python的print打印报编码错误的解决方法
错误类似如下提示: 'gbk' codec can't encode character '\xa9' in position 19672: illegal multibyte sequence 这个问题一般也就是在cmd中才会有。 在cmd中...
十点数据
博客
1年前
554
0
Urllib库添加Headers的方法
方法一:借助build_opener和addheaders完成 import urllib.request import os,sys,io #解决编码问题,修改默认编码为gb18030 sys.stdout = io.TextIOWrapper...
十点数据
博客
1年前
560
0
PYTHON Consider using the `--user` option or check the permissions.
ERROR: Could not install packages due to an OSError: [WinError 5] 拒绝访问。: 'D:\\Program Files (x86)\\Python\\Python39-32\\Lib...
十点数据
博客
1年前
1313
0
python module ‘mitmproxy.proxy‘ has no attribute ‘config‘问题解决
python module ‘mitmproxy.proxy’ has no attribute 'config’问题解决 原因是mitmproxy的版本太高,目前7.x的版本已经不是这样解决了,使用下面的语句降一下版本即可: pip insta...
十点数据
博客
1年前
1053
0
python3安装demjson报错
python3 安装 demjson 2.2.4 出现以下报错 error in demjson setup command: use_2to3 is invalid 由于 demjson 2.2.4 兼容python2和python3,当安装...
十点数据
博客
1年前
1081
0
pymysql (1129, "XXX.XXX.XXX.XXX' is blocked because of many connection errors; unblock with 'mysqladmin flush-hosts'")解决方法
原因: 同一个ip在短时间内产生太多(超过mysql数据库max_connection_errors的最大值)中断的数据库连接而导致的阻塞; 解决方法: 1、提高允许的max_connection_errors数量(治标不治本): ① 进入...
十点数据
博客
1年前
707
0
1
2
3
4
...
24
博主公众号:
博主微信:
热门文章
1.
爬虫系列之Pyppeteer:比selenium更高效的爬虫界的新神器
2.
LayUi的Table表格defaultToolbar工具栏的显示与隐藏(权限控制)
3.
Spring Boot 踩坑系列之Error resolving template
4.
LayUi的动态表格table中设置下拉框Select编辑器
5.
基于JavaScript的流程图
6.
一个不错的验证码打码平台
最新发布
1.
selenium突然如下报错时,selenium退回4.9.0即可
2.
html.unescape与HTMLParser().unescape使用区别
3.
AttributeError: module 'networkx' has no attribute 'from_numpy_m
4.
Python3安装textrank4zh实现分词关键词提取及摘要生成报错:AttributeError: module ‘networkx’ has no attribute ‘from_numpy_matrix’
5.
阿里云域名解析到非80端口
6.
新版知乎x-zse-96参数101_3_3.0版分析
最新评论
和游戏外挂类似
基于内存,让我想到了易语言,游戏内存挂的开发,类似的技术吗?
赞,感谢分享
目前自己在用的就是这种方式,几万个关键词,每天采集量有小一百万的量。目前时间范围限制在一天
感谢分享
充值完但没有积分