×
请登录
账号
密码
登录 Use it
博客
新媒体
活动
方案
爬虫
热点
标签
登录
注册
博主QQ
博主QQ:
博主微信
博主微信:
博主公号
博主公众号:
回到顶部
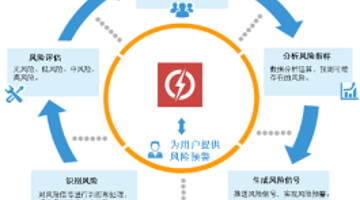
银行企业客户风险预警方案
扫码关注博主公众号(十点数据),可以获得100积分哦!! 风险预警设计方案说明书 1引言 1.1编写目的 风险预警主要对客户在XXX银行或其他银行出现的违约风险信息、财务风险信息、担保风险信息、经营管理风险信息、关联风险信息和其他预警信息实现主动...
十点数据
方案
1年前
3229
0
500
1
爬虫系列之数据质量监控实践篇:规则库梳理与设计
先前在《爬虫系列之数据质量监控(二):监控系统设计 》一文中,对采集中数据解析部分可能出现的各种异常,进行了大概的总结。比如:标题或内容中包含乱码、css样式、JavaScript代码等。 由于出现的异常可能千奇百怪,我们不可能提前想到所有现象。...
十点数据
方案
1年前
3028
0
爬虫系列之数据质量监控(三):kafka统一接口处理逻辑分析
(二)KAFKA统一数据推送接口 1)非空校验 处理逻辑:除标题为空数据直接存入异常MySQL库中外,其他类型的数据直接流到数据质量校验步骤进行分析; 2)数据质量校验 主要是根据每个字段设置的校验规则,对其进行相应的校验处理。 3)二次排重处理...
十点数据
方案
1年前
3788
0
爬虫系列之数据质量监控(二):监控系统设计
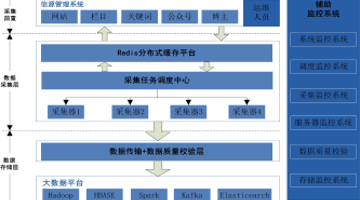
如需完整Word文档,请关注“十点数据”公众号获取。 二、数据监控流程图 三、流程详解 (一)信源系统 信源系统主要是用来管理各种规则,同时接收异常信息、并分析异常情况。 根据分析结果,把相应的信息推送给信源管理、采集人员等相关人员,以便优化采...
十点数据
方案
1年前
5294
0
爬虫系列之数据质量监控(一)
如需完整Word文档,请关注“十点数据”公众号获取。 一、概述 1.现状 最近SaaS平台、APP等产品,总是采集的数据中存在各种各样的问题,如标题解析成JavaScript代码,或者包含一段无用的字符、或者出现一个乱码字符串等等。 先前的那套监...
十点数据
方案
1年前
3814
0
一文带你了解solr部署全过程(word免费送)
扫码关注右侧博主公众号,回复“solr”,即可获取Word版原始文件。 一、环境准备 软件版本: Tomcat 版本:7.0.56 JDK 版本:1.7.0_71 SOLR 版本:4.8.1 软件包: apache-tomcat-7.0.56...
十点数据
方案
1年前
3181
0
一套价值十万的微信公众号采集解决方案
1 整体概述 1.1 编写目的 本文主要用于描述微信采集过程中,各流程节点的解决方案。详细介绍了采集架构、手机号购买注意事项、微信注册注意事项、微信号养号注意事项、公众号采集方式,以及采集过程中遇到的问题等。 1.2 整体架构 微信数据采集主要...
十点数据
方案
1年前
5529
0
1000
15
数据采集采集架构中各模块详细分析
先前简单的介绍了一下[《基于大数据平台的互联网数据采集平台基本架构》,今天主要介绍一下采集的各个环节中,应该如何处理,应该注意哪些方面。 废话不多说了,正文开始....... 第一:信源系统 其实就是采集任务管理系统,我们叫信源管理系统。主要包括...
十点数据
方案
1年前
6174
0
基于大数据平台的互联网数据采集平台基本架构
互联网的飞速发展将社会带入数据高度发达且公开的信息时代,数据对于企业经营、政府决策及社会动态分析等具有极其重要的作用,而如何大规模、快速采集数据成为技术焦点。 网络爬虫是按照一定规则自动游走爬取互联网文本网页的程序或者脚本。文本数据大多嵌套于网页...
十点数据
方案
1年前
7079
1
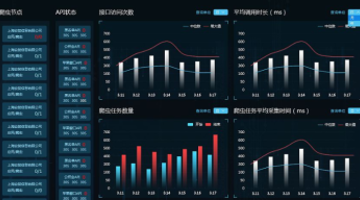
数据采集中,如何建立一套行之有效的监控体系?
在大批量、分布式数据采集中,由于涉及到的服务、系统、插件等较多,任何一处出现问题,都可能导致数据采集中出现异常。为了能够保证采集稳定、高效的运行,一套能够实时监控采集各个部分状态,在出现异常的时候,能够快速、有效的定位问题的监控体系,是必不可少的...
十点数据
方案
1年前
4793
0
1
2
博主公众号:
博主微信:
热门文章
1.
爬虫系列之Pyppeteer:比selenium更高效的爬虫界的新神器
2.
LayUi的Table表格defaultToolbar工具栏的显示与隐藏(权限控制)
3.
Spring Boot 踩坑系列之Error resolving template
4.
LayUi的动态表格table中设置下拉框Select编辑器
5.
基于JavaScript的流程图
6.
一个不错的验证码打码平台
最新发布
1.
selenium突然如下报错时,selenium退回4.9.0即可
2.
html.unescape与HTMLParser().unescape使用区别
3.
AttributeError: module 'networkx' has no attribute 'from_numpy_m
4.
Python3安装textrank4zh实现分词关键词提取及摘要生成报错:AttributeError: module ‘networkx’ has no attribute ‘from_numpy_matrix’
5.
阿里云域名解析到非80端口
6.
新版知乎x-zse-96参数101_3_3.0版分析
最新评论
和游戏外挂类似
基于内存,让我想到了易语言,游戏内存挂的开发,类似的技术吗?
赞,感谢分享
目前自己在用的就是这种方式,几万个关键词,每天采集量有小一百万的量。目前时间范围限制在一天
感谢分享
充值完但没有积分