






互联网的飞速发展将社会带入数据高度发达且公开的信息时代,数据对于企业经营、政府决策及社会动态分析等具有极其重要的作用,而如何大规模、快速采集数据成为技术焦点。
网络爬虫是按照一定规则自动游走爬取互联网文本网页的程序或者脚本。文本数据大多嵌套于网页程序代码中。数据采集的效率直接决定数据的有效及时性,数据的快速采集成为重中之重。
基于大数据平台的的互联网数据采集,可以有效适用于海量数据采集场景,为实现大规模分布式数据采集提供了工具,其架构主要包括信源管理、数据采集、数据传输、数据存储、系统监控等部分。采集架构图如下:
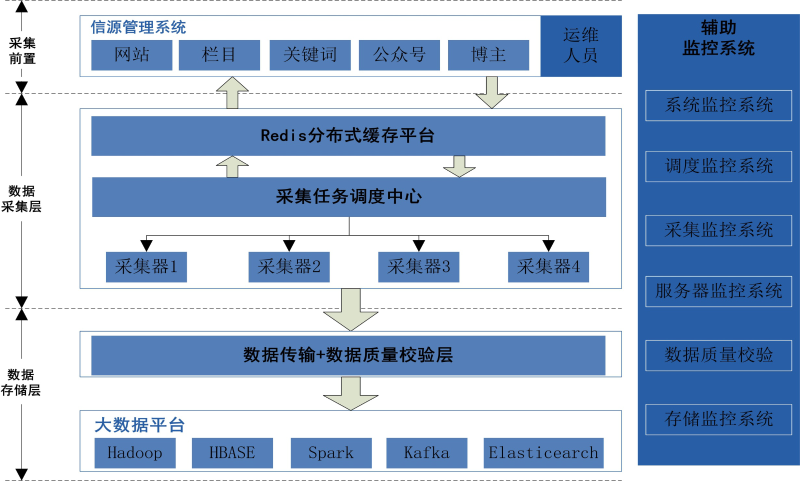
图中各部分功能介绍如下:
信源管理系统
主要用于采集任务的管理。其中主要包括:
① 网站:用于采集网站的管理
② 栏目:用于精确采集;
③ 关键词:用于搜索引擎采集。如:百度、搜狗搜索、Google搜索等;
④ 微信公众号:用于对特定公众号的监控;
⑤ 微博博主:用于对特定博主动态的监控;
⑥ 其他采集源管理。如电子期刊、APP客户端等
信源系统的主要作用:
① 方便运维人员对采集源的增删改查等;
② 根据信源的状态、正则状态等,实时监控网站;
③ 对于关键词搜素采集,便与实时增加/删除、启动/关闭采集;
④ 根据采集的实际情况,实时调整采集策略。如增加/删减采集器等;
数据采集层
数据采集层主要用于采集队列管理、调度、数据采集等,其中主要包括:
1.Redis缓存平台:主要用于缓存采集任务队列、过程数据(采集状态、列表数据等)等数据的临时存储;
2.任务调度中心:主要用于采集任务的调度,保证任务按设置的采集频率被采集。同时保证任务处理的唯一性(同一任务,同一时间,只能被一个采集器处理);
3.采集器:主要用于任务的处理。主要包括网页下载、数据结构化解析,任务监控等;
数据存储层
数据存储层主要用于采集数据的传输、分析、保存等,其中主要包括:
1.数据传输:采集器把解析出来的新闻、博客、公众号文章等内容,通过统一的SpringBoot微服务接口,推送到kafka中间件。同时,对数据的质量进行校验。主要要校验[发布时间](http://www.blog2019.net/tag/%E5%8F%91%E5%B8%83%E6%97%B6%E9%97%B4?tagId=31)、标题、正文等解析的准确度。同时,对数据进行一定的分析(打标签、特定信源监控)等;
2.大数据平台:主要包括Hadoop、HBASE、kafka、spark、ES等。各采集器采集的数据通过微服务接口,推送到kafka消息中间件,spark消费其中,把标题、时间、正文等创建ES索引,供业务查询使用,同时把完整的信息存入HBASE。
辅助监控系统
辅助监控系统主要用于监控各采集网站和栏目、采集调度服务、推送服务、采集器、大数据平台等,以保证其稳定、正常运转,其主要包括以下各子系统:
1.信源系统监控:主要监控网站、栏目、公众号、博主等状态,保证其正常访问;
2.采集监控:主要用于监控每个采集任务的状态,以便与对异常任务、数据漏采等情况进行排查。同时,根据记录的状态,亦可以校验网站、栏目等是否正常
3.服务器监控:主要监控服务器CPU、内存、硬盘等使用率,以及是否宕机。同时,根据服务器使用情况,合理部署采集器;
4.数据质量校验:主要用于实时监控数据质量,根据异常数据,反查信源等配置;
以上就是一个完整的采集平台大致包括的内容。

