






先前简单的介绍了一下[《基于大数据平台的互联网数据采集平台基本架构》,今天主要介绍一下采集的各个环节中,应该如何处理,应该注意哪些方面。
废话不多说了,正文开始.......
第一:信源系统
其实就是采集任务管理系统,我们叫信源管理系统。主要包括:
1.任务模块:网站、栏目、搜索引擎、关键词、模板、公众号、微博博主等。
2.资源管理模块:服务器、项目、索引等;
3.监控模块:网站、栏目、搜索引擎、服务器、采集器等模块。
4.调度模块:采集器创建、部署、启动、关闭、删除等;
下面对各个模块的作用、注意事项等做个简单的介绍。
1.任务模块
(1)网站、栏目/频道管理
先前在(《3人团队,如何管理10万采集网站?(最全、最细解读)》)一文中,有介绍网站、栏目如何批量添加等,这里就不在累述。
这里主要说一下如何在配置网站、栏目时,过滤掉与公司业务无关的信源。
其方法主要有两种。一是人工筛选;二是设置过滤词;当配置的网站或栏目的名称中包含词,则系统后台直接过滤掉,不再进行正则解析、保存等。
比如,我们的主要业务是金融、证券、保险、银行等行业。那么我们的过滤词可以包含以下几类:
① 地区名称;如:中国、北京、上海等。
② 蔬菜、水果等名称;如:白菜、苹果等。
③ 体育、娱乐、电影、时尚、奢侈品等类型词。
④ 健康、人文、文艺、文史、历史、美食类。
⑤ 女性、育儿、教育、旅游、研究、法律法规、政策等频道。
网站/栏目在采集时,还有一个最重要的点就是采集频率,在首次配置时可以遵循以下规律:
① 中央级媒体:首页10分钟,一级频道15分钟;二级频道20分钟,其他30分钟;
② 省级媒体:首页15分钟;一级频道20分钟;二级频道30分钟;
③ 市县等地方网站:首页60分钟;一级频道120分钟;二级频道240~720分钟;
上面是基本规律,配置时还需要根据实际情况,具体分析处理。如一些地方性网站,虽然小,但是和业务贴合度高,且每日发文也较频繁,那么就可以把采集频率设置为30分钟或者60分钟。
在网站/栏目采集加入常规化以后,就需要根据一段时间内的发文规律,自动分析出采集频率。这样,可以使我们的服务器等资源的利用率,达到最大化,减少浪费。
(2)搜索引擎管理
虽然说我们采集了很多网站,但是相对于整个互联网来说,还是九牛一毛。那么,我们能够通过什么方式,高效、低廉的获取我们所需要的数据呢?
搜索引擎是一个很好的补充。
通过分析我们产品、项目的业务需求,整理出相关的关键词,就能够通过搜索引擎,很快的获取到我们需要的一部分数据了。我们就能够较快的响应客户的需求,提高用户体验,提供下单率。
但是,搜索引擎比较多,为了我们能够灵活的进行添加、删除、修改等,同样需要集成到信源系统。同时,我们也能够在信源系统中,随时监控状态,实时调整采集策略。
(3)关键词管理
关键词的配置,主要注意以下几点:
① 每个关键词必须与一个项目关联;
② 每个关键词都要记录下提供者姓名;
③ 关键词添加时,同样需要经过排除词进行处理。过滤词可以与网站/栏目配置的同步使用;
(4)公众号
对于微信公众号的文章采集,就目前来说,能够实现批量,且较稳定、快速、高效的方法,就是基于手机XPosed插件的采集方式。
不过,该方式也存在不少缺点:
① 前期投入较大;
因为每个手机上只能安装一个XPosed插件,就只能hook一个微信号。而且每个微信号最多只能关注999个公众号,比如要监测100万公众号的话,就需要一千部手机。按一部手机800元,使用三年,第一年需要花费60万左右。加上10%损耗,平均35万/年。
② 微信号需求量大;
因为一个微信号最多只能关注999个公众号,如果要监测100万公众号,就需要一千个微信号,再加上10%的封号概率。第一年至少需要1100个微信号。
③ 运维较麻烦
主要体现在封号上。如果是临时封号的话,可以通过手机号解封。如果是永久封号,那就需要把当前微信号中关注的公众号,重新在其他微信号上进行关注监测了。这个过程需要二十天左右才能结束。
④ 公众号的关注比较麻烦
因为一个微信号一天只能关注四五十个公众号;
为了应对封号问题,我们在处理公众号时,需要注意一下几点:
① 每个公众号必须在数据库中和微信号进行管理,
② 手机必须按一定的规律进行编号
③ 手机和微信号之间在数据中必须进行关联。
(5)模板管理
我们现在已经逐渐放弃配置模板,倾向于通过训练自动处理了。
(6)微博博主管理
由于微博的搜索列表中,并未显示搜索词相关的所有信息,所以需要同时监测一部分博主,二者相互补充。
2.资源管理模块
(1)服务器管理:
做舆情或者数据服务的公司,数据采集涉及到的服务器至少也得几十台。为了便与掌握这些服务器什么时候到期、续费、以及服务器配置等情况,我们倾向于把服务器的管理,同任务调度一起设计,不使用云平台提供的控制端。 当然,网管可以使用云平台控制端,进行查询、监测服务器各项指标。
(2)项目管理:
在做搜索采集时,搜索词一般是根据项目或者产品的数据范围整理而来。所以,在添加元搜索关键词时,一般与项目绑定。所以,项目也就需要统一管理了。
(3)索引管理:
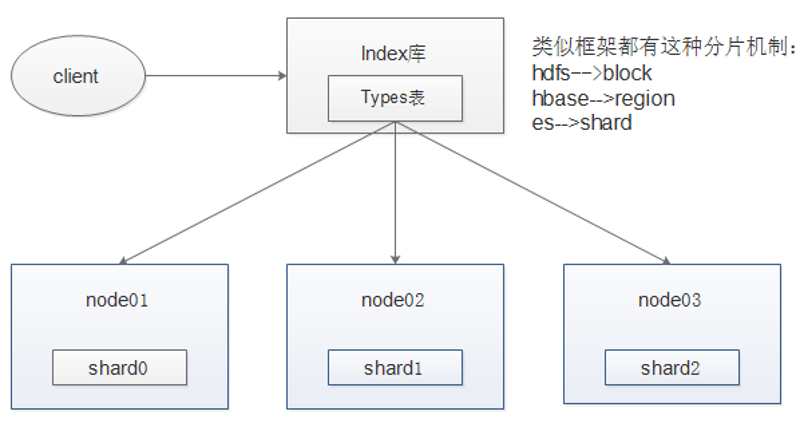
由于大批量数据采集中,每天采集到的数据量级至少在百万。所以,我们不可能把很长一段时间内采集下来的数据,全都放在一个ES索引库中。
我们在实际使用中,首先把信息分类。如:新闻、论坛、博客、微博、客户端、微信和纸媒等,如果采集有国外网站,可以加一个外媒类型。
虽然把数据按类型进行了归类,但是每一类数据也不可能始终存放在一个索引中。所以,还需要对索引按某一规律进行生成。如按时间,每周或者每月生成一个某一类型的索引。
为了提高ES集群的工作效率,我们可以根据实际业务需求,关闭距当前时间较长的冷索引,比如关闭半年以前生成的ES索引。这样能够减少服务器内存、硬盘的浪费,也能够提高热索引的查询速度,增强产品的用户体验。
同时,为了掌握ES集群中每个索引的情况,我们需要记录索引的创建时间、最后一次保存数据时间、索引名称、索引类型、数据量、数据类型、以及包含哪些字段等。
记录索引信息,一是为了方便了解当前各类型数据所在索引库;二是为了便与各类统计、报告所需数据导出等。
3.监控模块
网站、栏目、搜索引擎、服务器、采集器等监控就不在累述,先前的《数据采集中,如何建立一套行之有效的监控体系?》一文中有详细的介绍,大家可以翻看一下。
4.调度模块

调度模块是运维管理中最为重要的部分。
分布式大批量数据采集中,涉及到采集的网站、栏目或频道的数量级至少是万级、十万级,更有甚者是百万级。 涉及到的服务器少则三五台,多则三五十台,亦或是三五百台。每台服务器上又部署多个采集器等,如此数量级采集器的运维,没有一个专门的系统来处理,那是无法想象的。
调度模块主要负责采集器的增减、部署/上传、启动、关闭等,从而实现一键式部署,解放人力。
第二:数据采集
采集器在处理采集任务中,最重要的三部分是:网页下载、翻页、数据解析。其中各部分处理中需要注意的事项如下:
1.翻页
在大批量数据采集中,不建议设置翻页。主要是翻页信息的维护比较麻烦。为了不漏采数据,可以适度的增加采集频率,来弥补未翻页带来的影响。
2.标题
标题一般使用采集URL地址时A标签的值。然后在正文解析时进行二次校验,来纠正标题可能存在的错误。
3.发布时间处理
发布时间解析难免会出问题,但是绝对不能大于当前时间。
一般是清除HTML源码中css样式、JS、注释、meta等信息后,删除HTML标签,取内容中第一个时间作为发布时间。
一般可以统计一些发布时间标识,如:“发布时间:”,“发布日期”等。然后,通过正则表达式,获取该标识前后100个长度的字符串中的时间,作为发布时间。
第三:数据质量
1.标题处理;
标题一般容易出现以下三个问题:
① 以”_XXX网站或门户”结尾;
② 以“....”结束;
③ 长度小于等于两个字符;
针对上面的问题,我们可以使用列表标题与正文中的标题进行二次校验来纠正。
2.正文处理;
正文一般按数据类型,可以注意以下问题:
① 新闻、博客、纸媒、客户端和微信等正文需大于10字符;
② 论坛和微博等内容大于0即可;
③ 注意由于解析异常,导致的内容中存在css样式数据;
④ 格式化数据。删除多余的“
”、“ ”、空行等。
3.统一数据传输接口:
对于公司来说,有常规采集,还有基于项目、产品进行的定制采集。并且有些项目或产品定制脚本较多,如果数据保存方式(或者数据推送方式)不统一,一旦出现问题,就极难排查。而且还浪费时间、增加人力成本开销。
统一数据传输接口主要有以下优点:
① 异常前置,减少异常数据流入系统概率,提供用户体验;
② 数据质量监控,优化采集任务;
③ 多来源情况下数据排重,减少[数据分析](http://www.blog2019.net/tag/%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?tagId=90)压力;
④ 减少数据持久化中存现的问题,提供工作效率;
第四:统一开发模式
舆情或数据服务公司,数据采集人员相对较多,技术水平参差不齐。为了减少各级人员开发过程中的BUG量,可以提炼采集各个部分中,耦合较低的模块定制开发,然后制作成第三方插件,下发并安装到各开发人员的环境中。这样可以极大地减少开发中BUG的概率,有效地提供工作效率,
那么,哪些模块可以独立出来呢?
① 采集任务获取模块;
② 网页下载模块;
③ 发布时间、正文等解析模块;
④ 采集结果推送模块;
⑤ 采集监测模块;
通过对上面这五部分代码进行统一以后,至少可以节省40%的人力。
第五:采集的痛点:
1.网站改版****
网站改版以后,随之而来的就是信息正则、翻页正则、采集模板等失效,导致网站采集异常。不仅浪费资源,还会影响采集的效率。
尤其是最近一两年政府性网站,进行了一次全国性的大改版,历史配置的好多网站都采集不到数据了。
2.数据漏采
数据漏采,情况下就是下面的其中一种:
① 采集频率不对,导致信息跑到第二页等,无法采集到(因为采集翻页)
② 由于网站改版,导致信息正则或模板等配置异常;
③ 信息所在网站没有配置栏目,添加到采集任务队列;
④ 数据传输异常,导致数据丢失;如kafka异常,导致内存中所有数据丢失;
⑤ 网络抖动,导致正文采集异常;
上面的几个导致数据漏采的原因,都可以通过监测体系,很快的发现并定位问题。由于监控体系的建立,可以参考先前发表的《数据采集中,如何建立一套行之有效的监控体系?》一文。
第六:第三方数据平台
如果你是个人,只是简单的采集一些数据写个论文,或这个测试什么,那这篇文章看到这里就可以结束了;
如果你是做舆情或者数据分析的公司,第三方平台则是一个很好的数据补充来源。一方面,可以补充我们漏采的数据,提高用户体验。另一方面,还可以从他们的数据中,分析出信息的来源网站,补充我们自己的信源库。
主要的第三方平台或数据服务商有以下几个:
1.远哈SaaS平台
远哈舆情其实就是新浪舆情通。所以,远哈的微博数据应该是市面上最全、时效性最好的了。网站、客户端、纸媒等类型数据其实都差不多,就看投入的多少了。一般
2.铱星SAAS平台
3.智慧星光SaaS平台
铱星和智慧星光的数据都差不多,智慧星光的稍微好一点。
4.八友微信数据
特点:微信公众号文章数据还可以,每天的量在80~150万之间,他们的费用应该是市面上比较合适的。如果你们公司有这个需求,可以对接他们。微博等其他数据,暂时未对接过,质量如何不得而知了。
今天就说这些了。文笔不好,大家了解一下思路就好。哈哈......
大家要是有其他采集相关的问题想了解的,可以加下面的公众号留言啊!

