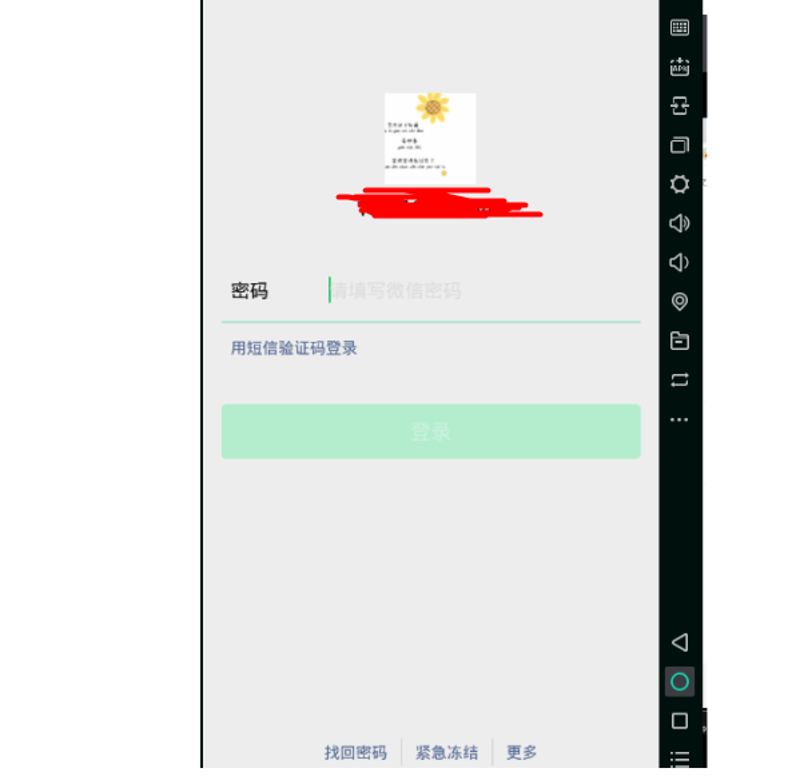
最近在做基于模拟器的微信自动添加好友的应用时,模拟器中的打开的微信总是会出现一些异常,如下图:
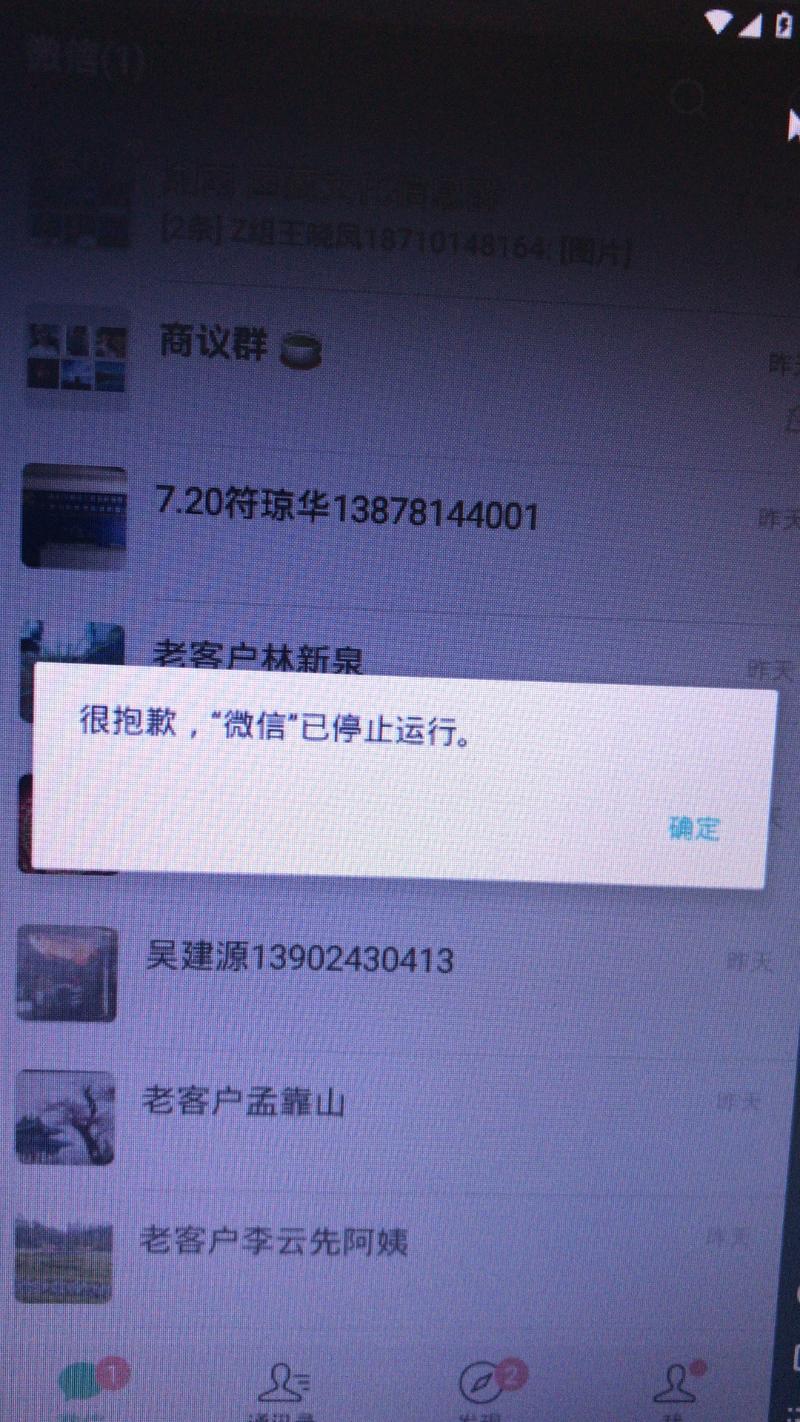
此时,就需要识别一下,然后重新启动模拟器。
有时,有些手机号对应的微信号不存在,如下图:
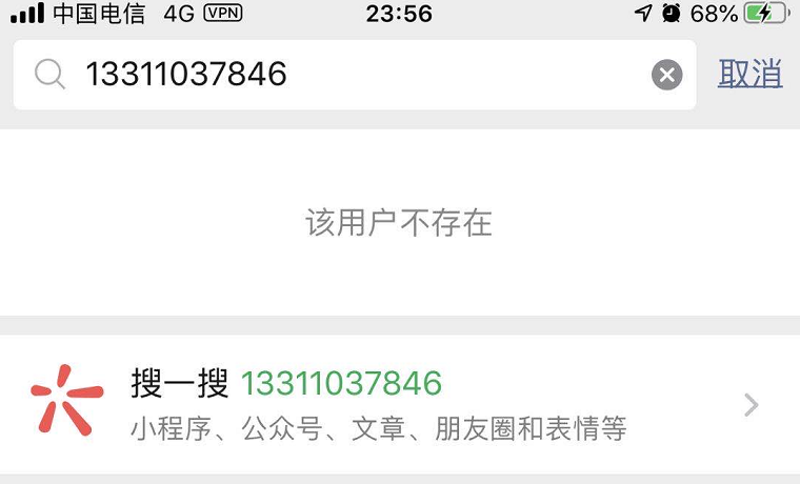
此时,就需要识别出提示信息(该用户不存在),然后决定下一步操作。
本来想基于Tesseract-OCR+pytesseract自己做一个简单的识别,但是中文识别效果太差,最后决定测试一下百度的免费识别接口,发现识别的效果还是挺好的,如下图:
百度图片识别接口获取步骤:
一:注册百度智能云账户
注册百度智能云账户。如果大家有百度搜索、百度贴吧、百度云盘、百度知道、百度文库等产品的账户,这里可以直接登录,他们是通用的。
二:创建应用
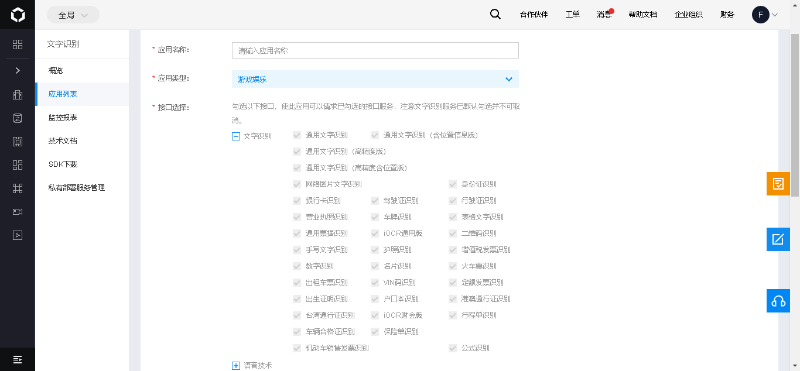
登录进入控制台,选择“产品服务”--->搜索“文字"--->选择“文字识别”--->"创建应用",如下图:
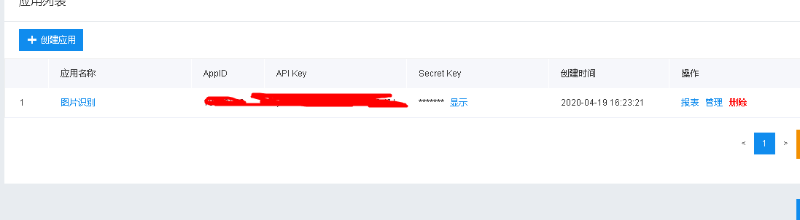
创建完以后,会显示如下图信息:
三:应用(接口调用)
由于我用的是Python,所以就展示一下Python的调用方式;
1》:获取session:
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=[你创建的要用的API Key]&client_secret=【你创建的要用的Secret Key】'
response = requests.get(host)
self.access_token = None
if response:
self.access_token = response.json()['access_token']
print("access_token:", self.access_token)
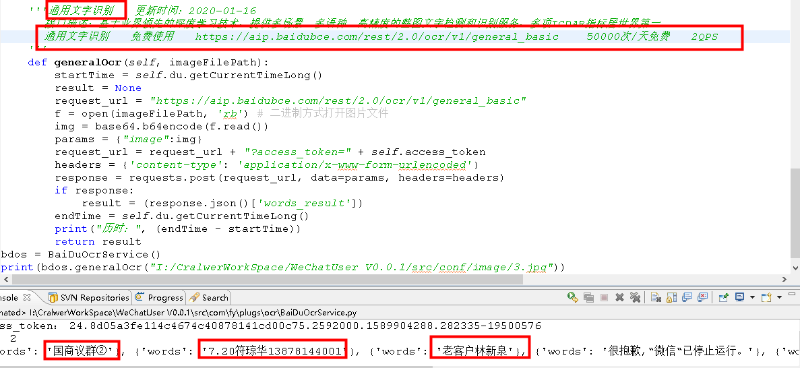
2》:调用接口,识别图片
'''通用文字识别 更新时间:2020-01-16
接口描述:基于业界领先的深度学习技术,提供多场景、多语种、高精度的整图文字检测和识别服务,多项ICDAR指标居世界第一。
通用文字识别 免费使用 https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic 50000次/天免费 2QPS
'''
def generalOcr(self, imageFilePath):
startTime = self.du.getCurrentTimeLong()
result = None
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
f = open(imageFilePath, 'rb') # 二进制方式打开图片文件
img = base64.b64encode(f.read())
params = {"image":img}
request_url = request_url + "?access_token=" + self.access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
result = (response.json()['words_result'])
endTime = self.du.getCurrentTimeLong()
print("历时:", (endTime - startTime))
return result
识别效果如下图: