






如需完整Word文档,请关注“十点数据”公众号获取。
二、数据监控流程图
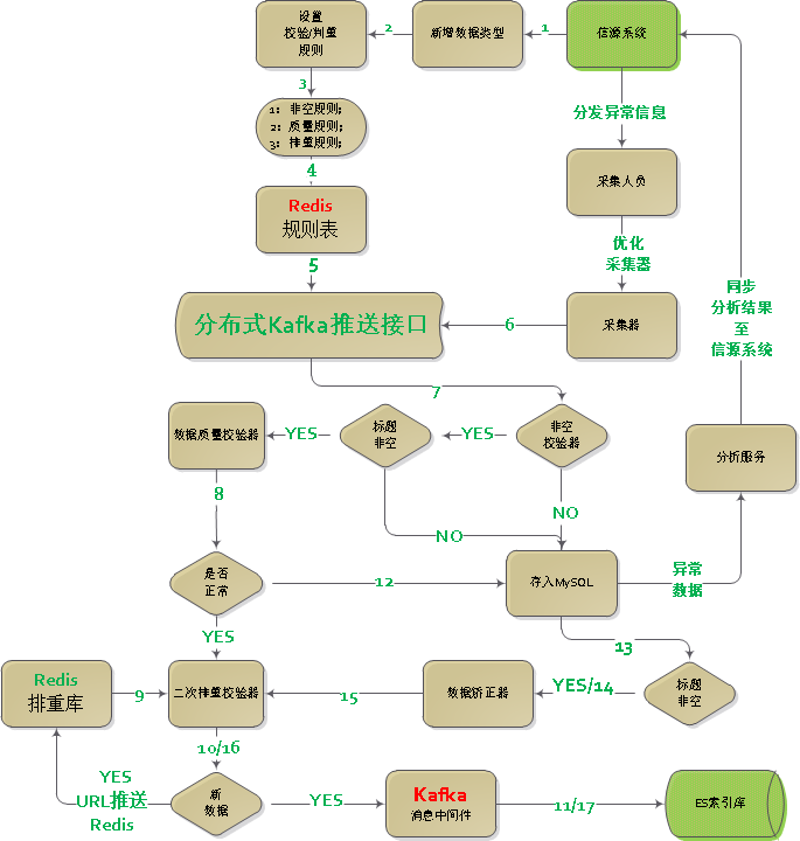
三、流程详解
(一)信源系统
信源系统主要是用来管理各种规则,同时接收异常信息、并分析异常情况。
根据分析结果,把相应的信息推送给信源管理、采集人员等相关人员,以便优化采集策略及采集器,从而达到采集闭环(采集--反馈--优化采集--采集)。
1)相关规则阐述:
设计数据校验规则的目:
① 为了保证流入产品的数据质量。
② 为了发现采集的不足之处,以便优化采集策略,完善采集器。
终极目标是提高数据产品的用户体验,增强用户粘性。
校验规则说明
只有标题非空的信息,才会进行数据质量校验,数据矫正等后续操作。
规则分类说明
① 非空校验规则;type=1
② 数据质量校验规则;type=2
③ 数据清洗规则;type=3
④ 二次排重规则。type=4
非空规则
具体的判断规则,根据索引字段管理中配置为准。包括但不限于下面几方面:
① 标题/评论是否非空;
② [发布时间](http://www.blog2019.net/tag/%E5%8F%91%E5%B8%83%E6%97%B6%E9%97%B4?tagId=31)是否非空;
③ 内容是否非空;
④ 采集时间是否非空;
⑤ 插入时间是否非空;
⑥ 数据类型是否非空;
⑦ 如果为空,就无法判断该条数据使用那一类型的校验规则;
⑧ Kafka根据该字段值,来判断数据存入那个ES索引中;
⑨ 采集人ID标识是否非空。
⑩ 设计该字段的主要用了记录数据来源,以便快速定位到人。
⑪ 新闻或网站类型的数据中site_id和site_name不可为空;
注释事项:
只有标题/评论内容不为空的信息,才可以流入后续环境。
数据质量规则
1)标题:
① 标题是否有乱码;
② 是否出现日期信息。如:
③ 标题是否以”XXXXXX_XXX网站/门户网站”等结束;
④ 标题是否包含JS、CSS样式等。
⑤ 标题是否包含HTML转义字符等;如: ;
⑥ 包含特殊格式。比如:
等等
2)正文/评论:
① 是否包含乱码;
② 是否包含JS、CSS;
③ 是否包含无用内容。如:打开APP、查看更多、精彩图片、展开全文、 扫一扫、扫码关注等等;
④ 内容和标题描述是否一致;
⑤ 内容是否包含转义字符等;如下图所示:
⑥ 包含特殊重复格式。比如:多个”
”、换行等同时出现 ⑦ 是否包含版权信息。如:独家稿文,禁止转载等字样
3)发布时间:
① 是否大于采集时间;
② 长度否是19位;
③ 格式是否为:yyyy-MM-dd HH:mm:ss。
数据清洗规则
1)根据域名
根据域名过滤掉整个网站的数据。这种情况主要为应对一些域名异常的情
况。比如一些网站实际跳转到一些赌博网站等
2)根据关键词进行特定清洗
① 包含某个关键词整行删除。
② 删除某个特定关键词;
二次排重规则
1)排重依据字段。
可以单个字段,也可以是多字段联合排重。比如微信使用“公众号名称”+“标题”的二次排重。
2)排重规则具有唯一性
一种类型的数据只能设置一种排重规则;
2)系统功能设计
规则库管理
① 非空规则的添加、编辑、删除、查询等;type=1
② 数据质量校验规则的添加、编辑、删除、查询等;type=2
③ 数据清洗规则的添加、编辑、删除、查询等;type=3
④ 默认规则参考《相关规则阐述》中《非空规则》、《数据质量规则》和《数据清洗规则》;
⑤ 规则下需要可以添加相应的判断关键词。
Kafka统一推送接口管理
① 能够实现现有接口的添加、编辑、删除、查询等管理。同时把信息同步到Redis库中。格式如③中图所示;
② 接口服务记录中须包括:[部署](http://www.blog2019.net/tag/%E9%83%A8%E7%BD%B2?tagId=13)的服务器IP、接口端口号等信息;
③ 由于是分布式部署,每个接口会有多个地址URL,如下图所示。
④ 接口在Redis中的存储方式:key=方法名,value=拼接字符串
数据类型管理
数据类型管理
① 能够实现对数据类型的添加、编辑、删除、查询等基本功能;
② 该功能需可以添加排重依据字段,字段可以是单个,或者是组合;
③ 该功能需可选择数据推送接口地址URL;通过接口方法名进行关联;
④ 数据类型一般可以分为:新闻(或网站)、论坛、博客、微博、纸媒、外媒、客户端、微信、视频、广播、电视台、评论等;
⑤ 数据类型需要通过ES索引类型进行关联;
⑥ 数据类型需要和人员相关联。
索引字段管理
① 各类型数据对应的索引库中的field字段;
② 包括但不限于:字段名称、类型、长度、是否为空、是否约束键(ES主键);
③ 该功能下可以添加非空规则、数据质量校验规则和清洗规则等;
校验规则设置
① 功能大致结构,可以使用树状方式展示,树节点由数据类型,以及其字段组成。
点击数据类型时,显示该类型的排重规则;
点击字段时,显示已设置的非空规则、数据质量校验规则和清洗规则等
② 点击不同节点,可以添加相对于的规则。同时,能够对已设置的规则进行编辑、删除等;
采集人员管理
采集人员管理暂时使用信源系统用户功能,根据实际需要对其进行优化。
异常数据管理
1)异常数据需要记录的字段:
① 标题(exe_title)
② 链接(exe_url)
③ 域名(exe_domain):用于统计网站异常情况;
④ 数据类型(exe_group_id):用于统计个数据类型的异常数据情况;
⑤ 索引类型(exe_index_type)
⑥ 发布时间(exe_ptime)
⑦ 采集时间(exe_gather_time)
⑧ 校验时间(exe_check_time)
⑨ 异常使用的规则(exe_rule_id):用于按规则统计;
⑩ 采集人(exe_crawler_id):用于统计各采集人员采集数据的质量;
⑪ 采集器ID(exe_gahter_id):用于快速定位采集器;
2)具有编辑推送功能
如果数据和业务贴合度较高,或者是负面信息,为了保证数据的时效 性,需要人工对其进行编辑(运维优化过程需要时间,会影响数据时效性),并推送至kafka,以提高产品的用户体验。
① 能够有部分统计功能,以便分析、总结某些规律性问题。
1)能够按校验规则进行统计
2)能够按采集人员进行统计;
3)能够按网站进行统计;
4)能够按数据类型进行统计;
3)Redis规则库设计
存储格式
为了提高数据质量校验和排重的性能,以数据类型作为key,该类型下所有的适用规则,包括:非空规则、数据质量校验规则、清洗规则,以及二次排重规则等,组合成一个JSON字符串作为value,保存到Redis规则库中。
为了保证处理方式统一,格式可以与kafka统一接口的存储格式相同。

