(二)KAFKA统一数据推送接口
1)非空校验
处理逻辑:除标题为空数据直接存入异常MySQL库中外,其他类型的数据直接流到数据质量校验步骤进行分析;
2)数据质量校验
主要是根据每个字段设置的校验规则,对其进行相应的校验处理。
3)二次排重处理:
由于Bloom Filte中的元素只可以添加,不可以被删除。又由于数据量较大(每天5000W左右),长时间会耗费很多内存资源,投入较大。
同时,排重库中并不需要保留所有的历史记录,比如只保留最近半年或一年的记录,如何自动清除历史记录,又成了新的问题。
所以,最后决定使用Redis的XX类型数据,利用Redis自身特性,对主键key设置自动过期时间,减少运维的难度和成本。
4)数据清洗处理
目前主要是对异常网站和特殊关键词进行清除。
处理对象:【正常】数据
5)数据矫正处理:
由于舆情系统对数据的时效性有较强的要求,为了保证数据覆盖度,减少人工补录带来的工作量,需要对发现的异常数据进行二次加工,然后推送到kafka。
处理对象:【异常】数据
标题矫正
根据数据质量校验中的五条规则,对数据进行二次清洗,然后推送到流程下一步。如果标题为空,则直接丢弃。 内容矫正
内容矫正主要分两种情况:空和非空。其各自的处理逻辑如下所示:
1)内容为空
此时进行一下处理:
① 使用URL调用正文获取接口,进行二次获取;
② 如果仍然为空,则使用标题作为内容进行推送,但是进行标识,以便kafka进行分发时,不发送信息到APP
客户端,增强用户体验;
2)内容非空
此时主要更具数据质量校验中的检测结果,对其进行二次清洗。主要包括:删除html内容,清楚特殊关键词、乱码等情况。
发布时间矫正
主要是根据非空规则和质量规则中,针对发布时间的校验结果,对其做相应的矫正。如:
① 为空,则用[采集](http://www.blog2019.net/tag/%E9%87%87%E9%9B%86?tagId=61)时间填充
② 大于采集时间,则用采集时间填充;
③ 格式不符合要求,则规范为”yyyy-MM-dd hh:mm:ss”格式等。
URL矫正
1)临时参数矫正
该种情况在搜索采集时比较常见。一般情况下是每个链接后面加一个时间戳参数,每搜索一次变一次,导致数据大量重复。所以,需要清除临时参数,还原链接本貌。比如:搜狗微信搜索采集时。
1)HTTP和HTTPS协议矫正;
有些信息可能因为来源的不同,导致网络协议不同,链接其实是指向同一条信息。此时,需要对http和https进行矫正、统一。
网站名称矫正
1)根据域名矫正
由于元搜索采集的信息,可能会没有网站名称信息,需要和信源系统进行关联出,进行填充。
数据类型矫正
1)根据域名矫正
把某一域名的数据全部更改为新的数据类型。
该种情况主要出现在综合搜索、或者栏目类型配置错误的情况,导致kafka数据分发异常,影响产品用户体验。
比如骂街的评论信息错误标识为新闻,导致只显示新闻信息的APP等产品的用户体验降低;
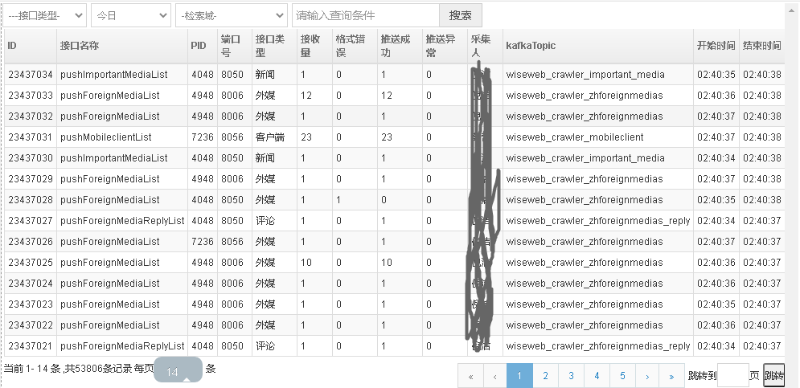
6)数据推送日志
需记录字段
包括但不限于:
① 接口服务ID
② 接口名称(方法名)
③ 接口接受请求时间
④ 推送结束时间
⑤ 接口接受数据量
⑥ 校验异常数据量
⑦ 推送kafka成功量
⑧ 推送kafka失败量
⑨ Kafka的Topic名称
⑩ 推送人(信源系统用户ID):以便快速定位采集人
⑪ 采集器ID:以便快速定位采集器,查询相关问题