






数据采集中,发布时间解析的正确与否,直接关系着使用数据的产品的质量。一般在做做大规模数据爬取时,都会整理一下发布时间规律,如特殊关键字,时间正则等。下面介绍一下,我在工作中处理的具体步骤。
1:收集发布时间标识词
一般情况下,标识发布时间的关键词有:更新时间:、发布日期:、发表时间:、发稿时间:、发布于:、编辑日期:、发布于:等。通过这些特殊关键词,可以高效、准确的判断出时间所在位置,提供解析的准确率。
2:收集发布时间正则
发布时间的正则表达式,一般情况下主要有一下九种:
(\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2})
(\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2})
(\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2})
(\d{4}-\d{1,2}-\d{1,2})
(\d{2}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2})
(\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2})
(\d{1,2}-\d{1,2})
(\d{1,2}:\d{1,2}:\d{1,2})
(\d{1,2}:\d{1,2})
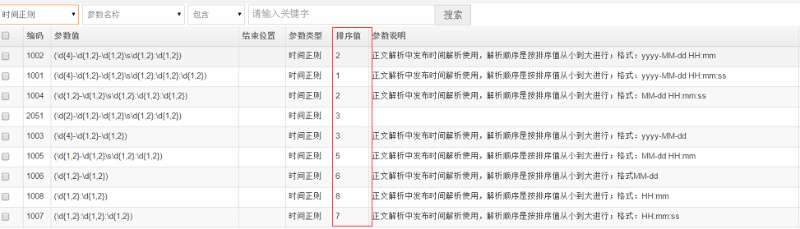
使用的过程中,需要注意这九种表达式的顺序。由于我在使用过程中,发布时间标识词与正则表达式,是在一个系统中统一管理。
所以,对每个标识词和表达式进行了排序,排序值越小,越先处理。如下如:

3:处理特殊时间格式
特殊时间格式如:“分钟前”、“小时前”、“天前”、“周前”、“今天”等。主要把这些时间转换为正常的时间格式,便与后续的解析。
4:HTML源码预处理
1:删除多余的HTML标签
删除meta、style、script、link、select、input、button、img等标签,消除这些标签中的值对解析的影响;
2:特殊标签处理
替换“”、"<span"、“
”等为“ ”
3:特殊字符处理
主要是对时间进行统一化、规范化。如“年”、“\”、“/”、“月”等替换为“-”;“日”、"T"等替换为“ ”等;
4:删除HTML所有的标签、特殊符号、字母等
5:根据收集的发布时间说明词,截取HTML源码
if self.keywords != None:
for kw in self.keywords:
try:
index = 0
if kw in html:
index = html.index(kw)
if(index > 1):
begin = 0
end = index + 100
if index >= 100:
begin = index - 100
else:
begin = index
html = html[begin:end]
break
except : print(traceback.format_exc())
6:替换所有的汉字为“ ”,同时规范字符串
5:解析发布时间
1:根据收集的时间正则,解析发布时间
2:根据获取时间时使用的正则,规范发布时间
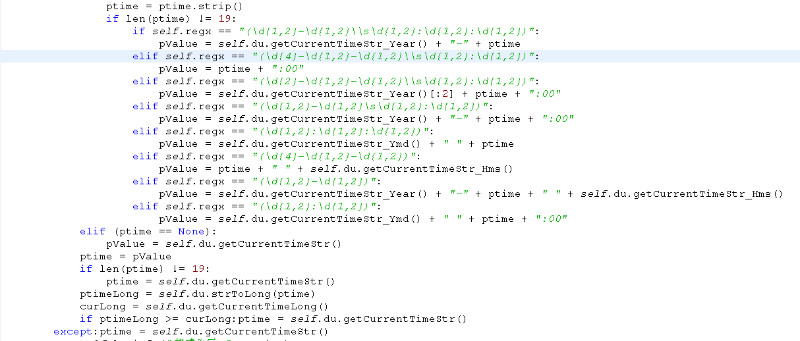
3:判断当前时间是否合法。主要是判断解析出的时间是否大于当前时间,如果大于,则用当前时间填充。避免影响后续产品的数据使用。

