






先前在《爬虫系列之数据质量监控(二):监控系统设计 》一文中,对采集中数据解析部分可能出现的各种异常,进行了大概的总结。比如:标题或内容中包含乱码、css样式、JavaScript代码等。
由于出现的异常可能千奇百怪,我们不可能提前想到所有现象。此时,就需要根据目前已经发现的问题,总结出一套能够灵活应对不同情况的规则库。
其目的就是在数据持久化接口处,对接收的所有数据,依据信源系统中配置的规则进行校验,以判断采集到的数据的准确性,便与改进采集器或脚本,优化数据质量,提高产品的用户体验。
一. 规则库必须是抽象的规则,而不是具体表象。
通过对《爬虫系列之数据质量监控(二):监控系统设计》 中描述的各类规则进行抽象,大致可以总结出以下规则。
如下表所示:
序号 分类 规则细则
1 校验规则 A字段值长度小于阀值A
2 校验规则 A字段的值是否包含CSS样式
3 校验规则 A字段的值是否有乱码
4 校验规则 A字段值中汉字长度小于阀值A
5 校验规则 A字段值是否符合yyyy-MM-dd HH:mm:ss时间格式
6 校验规则 A字段值等于阀值A
7 校验规则 A字段值大于阀值A
8 校验规则 A字段值长度大于阀值A
9 校验规则 A字段值长度等于阀值A
10 校验规则 A字段的值是否包含JavaScript代码
11 校验规则 A字段值与字段B值相同
12 校验规则 A字段值包括规则库中配置阀值,或包括接口配置阀值A
13 校验规则 A字段值以规则库中配置阀值结尾,或以接口中阀值A结尾
14 校验规则 A字段值是否包含日期
15 清洗规则 A字段值内容格式化
16 清洗规则 A字段值包含阀值A时,则删除A字段值中阀值A字符串
17 清洗规则 A字段值包含阀值A字符时,直接丢弃
18 清洗规则 A字段值转义字符还原
19 矫正规则 A字段时间大于B字段时间,则A字段值=B字段值
20 矫正规则 A字段值包含阀值A,则:B字段值=阀值B
21 矫正规则 A字段值包含阀值A,则A字段值中的阀值A替换为阀值B
目前整理的上述14条数据质量校验规则,基本上可以应对80%以上的异常。
至于清洗和矫正规则,则尚需要根据实际的业务规则,进行相应的补充。
二. 规则库的逻辑实现
在抽象出相应的规则库以后,需要根据规则库的描述,进行后端编码的逻辑现实,把文字描述用代码进行实现。具体实现逻辑类似下述两个规则:
1. 如规则1(A字段值长度小于阀值A)
代码实现:
public Boolean isALengthLtB(MonitorRule mr, MonitorRuleRelation mrr,Object oneData) {
//判断A字段及A阀值不为空
if (!StringUtils.isNotBlank(mrr.getInterAField())|| !StringUtils.isNotBlank(mrr.getThresholdA()))
return false;
Object aFieldValue = Reflect.getObjectXField(oneData, mrr.getInterAField());
//阀值A必须为数字;
if (!BooleanRegular.isNumber(mrr.getThresholdA()))
return false;
//判断字段A的值不为空;
if (!StringUtils.isNotBlank(aFieldValue)) return false;
Double value = Double.parseDouble(mrr.getThresholdA());
if (aFieldValue.toString().length() < value.intValue())
return true;
return false;
}
使用场景:如判断解析的标题或正文必须大于某个长度,否则认为解析异常。
2. 如矫正规则19(A字段时间大于B字段时间,则A字段值=B字段值)
代码实现:
public Object aGTb(MonitorRule mr, MonitorRuleRelation mrr, Object oneData) {
if (!StringUtils.isNotBlank(mrr.getInterAField())|| !StringUtils.isNotBlank(mrr.getInterBField()))
return oneData;
Object a = Reflect.getObjectXField(oneData, mrr.getInterAField());
Object b = Reflect.getObjectXField(oneData, mrr.getInterBField());
if (!StringUtils.isNotBlank(a) || !StringUtils.isNotBlank(b)) // 不为空
return oneData;
if (!BooleanRegular.isDate(a.toString()) || !BooleanRegular.isDate(b.toString()))
return oneData;
// 必须是19位时间格式;
if (a.toString().length() == 19 && b.toString().length() == 19) {
long aLong = DateUtil.stringToLong(a.toString(),
DateUtil.year_month_day_hour_mines_seconds);
long bLong = DateUtil.stringToLong(b.toString(),
DateUtil.year_month_day_hour_mines_seconds);
if (aLong > bLong) {
oneData = Reflect.setObjectXField(oneData,mrr.getInterAField(), b);
}
}
return oneData;
}
使用场景:如解析出的发布时间大于采集时间,则使用采集时间填充发布时间
三. 规则库与kafka统一接口的关系处理
规则库最终是用在kafka统一接口处,以便对接收的数据进行校验,找出异常情况。那么,他们如何进行关联呢?主要有以下两步:
1. Kafka统一接口与ES索引库进行关联
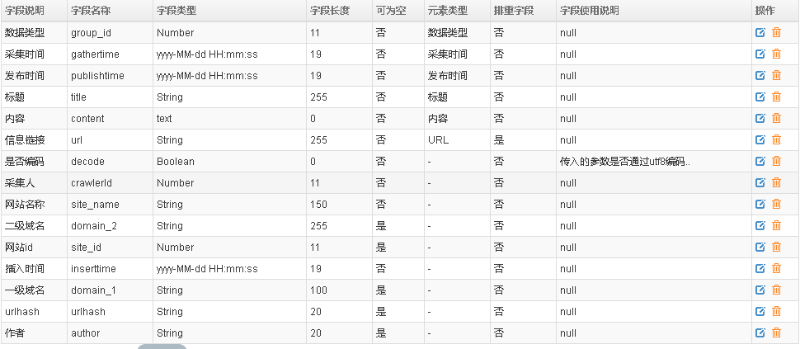
由于kafka的每一个对外服务接口,均对应一个唯一的ES索引库,所以接口接收的数据属性字段,必须与索引库一致。所以,在信源系统中的接口列表处,添加与ES索引对应属性信息。如下图客户端接口的配置信息:
Kafka统一接口中,数据类型为客户端的数据推送接口如下:

接口与ES索引对应的字段信息如下:
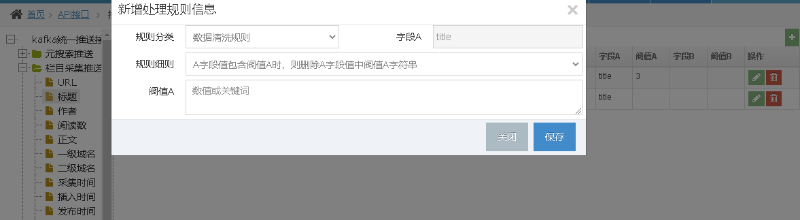
2. 给接口字段添加校验规则
比如需要给网站推送接口的标题字段添加清洗规则,则可以如下图操作。
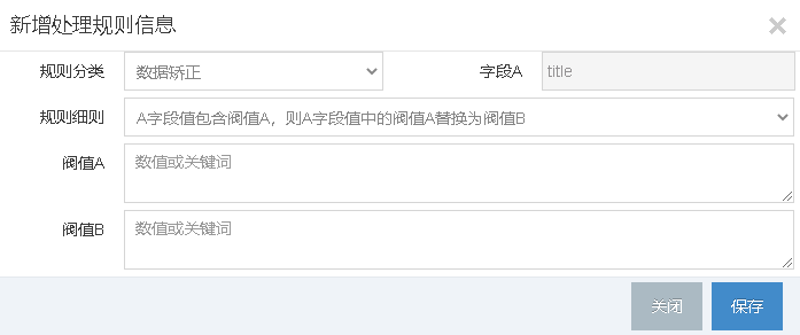
或者添加矫正规则:
最终添加完毕以后如下图所示:

四. kafka统一接口的校验处理
由于信源系统中已经配置了接口和规则库之间的关系,其中二者是通过接口方法名称和规则库处理逻辑(规则库处理逻辑:是规则库后台处理逻辑的方法名称)进行关联。如小图所示:
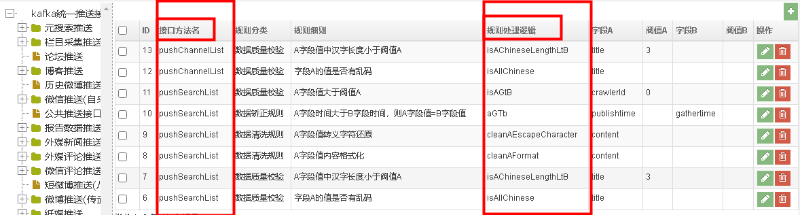
然后,在接口方法中通过类全路径,以及规则处理逻辑方法名,通过反射的方式进行动态调用。这样就可以根据字段配置的处理规则,灵活地进行各种规则的校验。
具体处理的代码类似下面:
import java.lang.reflect.Method;
import java.util.concurrent.Callable;
public class DynamicTask implements Callable<Object> {
// 该参数为待调用的类名和方法名;格式:java.tools.executors.dynamic.TestClass.test2
String classMethon;
// 该参数为为调用classMethon方法需要传入的参数集合 ;
Object[] arguments;
/**
* @param classMethon
* 类包.方法名。如:fy.java.tools.executors.dynamic.TestClass.test2(
* 调用TestClass的test2方法)
* 注意:classPackage包路径中不能有'_'、'-'等特色字符,否则无法执行;
* @param arguments 待调用方法需要的参数,参数顺序必须和方法中的额参数顺序相同;
*/
public DynamicTask(String classMethon, Object[] arguments) {
this.classMethon = classMethon;
this.arguments = arguments;
}
public Object call() throws Exception {
String classPackage = this.classMethon.substring(0, this.classMethon .lastIndexOf("."));// 类名
String methodName = this.classMethon.substring(this.classMethon .lastIndexOf(".") + 1);// 方法名;
Class<?> service = Class.forName(classPackage);
Object result = null;
Class<?>[] parameterTypes = null; // 获得参数的类型
try {
Method[] methods = service.getMethods();
for (Method method : methods) {
String mName = method.getName();
if (methodName.equals(mName)) {
parameterTypes = method.getParameterTypes();
break;
}
}
/**
* service是服务器端提供服务的对象,但是,要通过获取到的调用方法的名称,
* 参数类型,以及参数来选择对象的方法,并调用。获得方法的名称
*/
try {
// 通过反射机制获得方法
Method method = service.getMethod(methodName, parameterTypes);
// 通过反射机制获得类的方法,并调用这个方法
result = method.invoke(service.newInstance(), arguments);
} catch (Throwable e) {
e.printStackTrace();
System.out.println(arguments.toString());
}
} catch (Throwable e) { e.printStackTrace() ;}
return result;
}
}
上面就是数据质量校验前后台的大致处理逻辑,希望对各位有一定的参考意义。
更多内容请关注公众号:十点数据。大家一起学习,一起进步。

