






相关阅读:
字节跳动面试锦集(一):Android Framework高频面试题总结
 昨天有一个网友说,他最近面试了几家公司,有一个问题被问到了好几次,每次都回答的不是太好。
昨天有一个网友说,他最近面试了几家公司,有一个问题被问到了好几次,每次都回答的不是太好。
面试官:比如有10万个网站需要采集,你有什么方法快速的获取到数据?
想回答好这个问题,其实需要你有足够的知识面,有足够的技术储备。
最近,我们也在招聘,每周都会面试十几个人,感觉合适的也就一两个,大多数和这位网友的情况差不多,都缺乏整体思维,那怕那些有三四年工作经验的老司机。他们解决具体问题的能力很强,却很少能由点及面,站在一个新的高度,全面思考问题。
10万个网站的采集覆盖度,已经比大多数的专业舆情监控公司的数据采集范围都广了。要达到面试官说的采集需求,就需要我们从网站的收集,直到数据存储的各个方面进行综合考虑,给出一个合适的方案,以达到节省成本,提高工作效率的目的。
下面我们就从网站的收集,直到数据存储的各方面,做个简单的介绍。
一、10万个网站从哪里来?
一般来说,采集的网站,都是根据公司业务的发展,逐渐积累起来的。
我们现在假设,这是一个初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何收集到这10万个网站呢?可以有以下几种方式:
1)历史业务的积累
不管是冷启动,还是什么,既然有采集需求,一定是有项目或产品有这方面的需求,其相关的人员前期一定调研过一些数据来源,收集了一些比较重要的网站。这些都可以作为我们收集网站和采集的原始种子。
2)关联网站
在一些网站的底部,一般都有相关网站的链接。尤其是政府类型的网站,通常会有下级相关部门的官网。
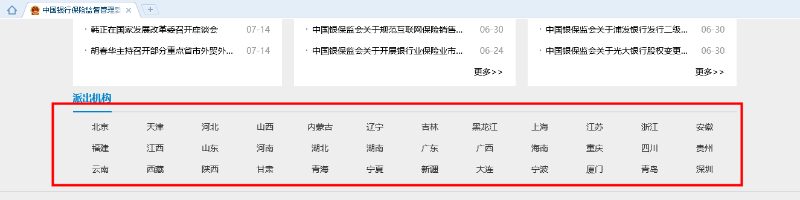
3)网站导航
有些网站可能为了某种目的(比如引流等),收集一些网站,并对其进行归类进行展示,以方便人们查找。这些网站可以快速的为我们提供第一批种子网站。然后,我们再通过网站关联等其他方式获取更多的网站。

4)搜索引擎
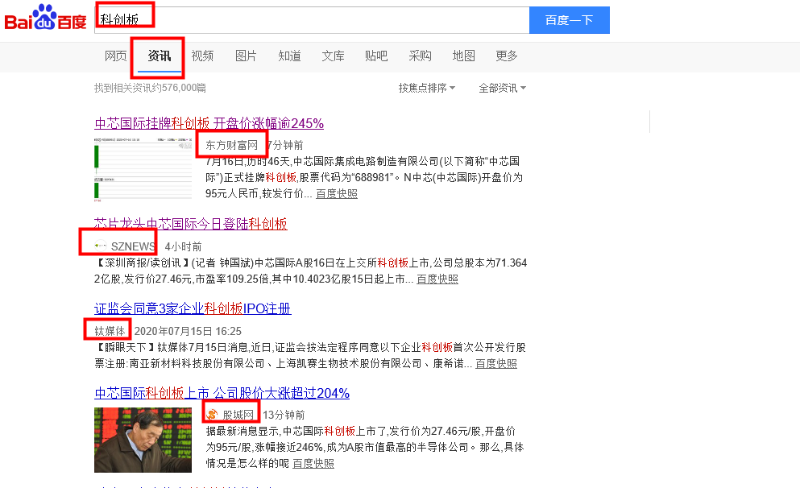
也可以准备一些与公司业务相关的关键词,去百度、搜狗等搜索引擎中搜索,通过对搜索结果进行处理,提取相应的网站,作为我们的种子网站。
5)第三方平台
比如一些第三方的SaaS平台,都会有7~15天的免费试用。所以,我们就可以利用这段时间,把与我们业务相关的数据采集下来,然后提取出其中的网站,作为我们初始采集种子。
虽然,这种方式是最有效,最快的网站收集方式。但是在试用期内,获取10万个网站的可能也极小,所以尚需要结合上述的关联网站等其他方式,以便快速获取所需网站。
通过以上五种方式,相信我们可以很快的收集到,我们需要的10万个网站。但是,这么多网站,我们该如何管理?如何知道其正常与否呢?
二、10万个网站如何管理?
当我们收集到10万个网站以后,首先面对的就是如何管理、如何配置采集规则、如何监控网站正常与否等。
1)如何管理
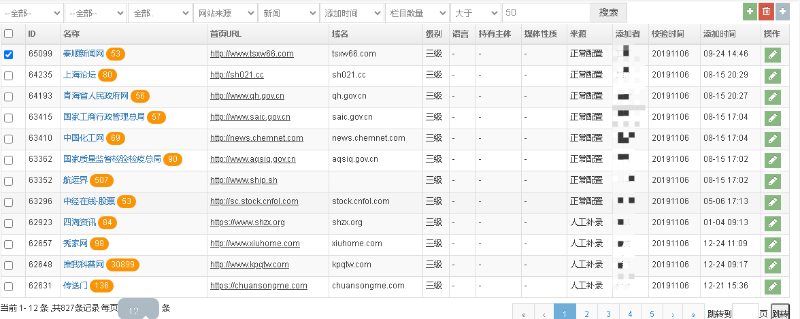
10万个网站,如果没有专门的系统来管理,那将是一场灾难。
同时,可能由于业务的需要,比如智能推荐等,需要我们对网站进行一些预处理(比如打标签)。此时,一个网站管理系统将是必须的。
2)如何配置采集规则
前期我们收集的10万个网站只是首页,如果只把首页作为采集任务,那么就只能采集到首页很少的信息,漏采率很大。
如果要根据首页URL进行全站采集,则对服务器资源消耗又比较大,成本过高。所以,我们需要配置我们关心的栏目,并对其进行采集。
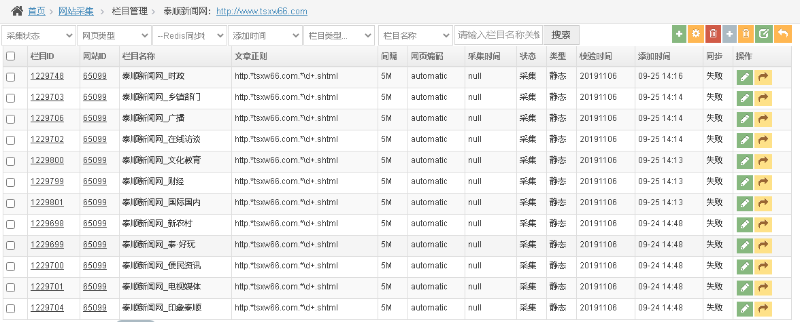
但是,10万个网站,如何快速、高效的配置栏目呢?目前,我们以自动解析HTML源码的方式,进行栏目的半自动化配置。
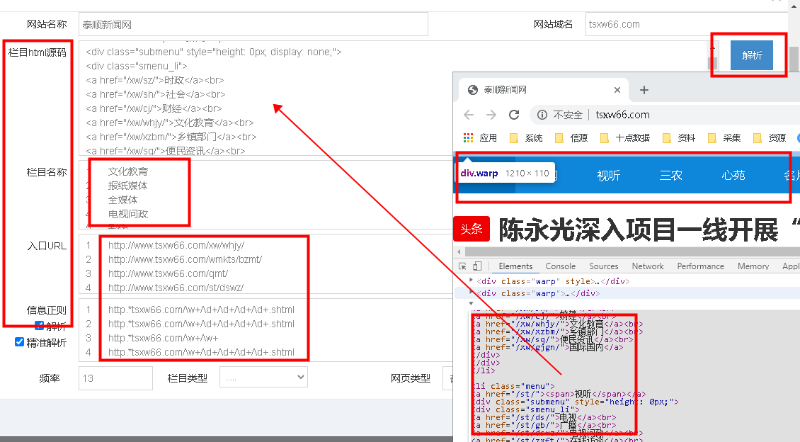
当然,我们也试验过机器学习的方式来处理,不过效果还不是太理想。
由于需要采集的网站量达到10万级别,所以一定不要使用xpath等精确定位的方式进行采集。否则,等你把这10万网站配置好,黄花菜都凉了。
同时,数据采集一定要使用通用爬虫,使用正则表达式的方式来匹配列表数据。在采集正文时,通过使用算法来解析时间、正文等属性;
3)如何监控
由于有10万网站,这些网站中每天都会有网站改版,或者栏目改版,或新增/下架栏目等。所以,需要根据采集的数据情况,简单的分析一下网站的情况。
比如,一个网站几天都没有新数据,一定是出现了问题。要么网站改版,导致信息正则失效常,要么就是网站本身出现问题。

为了提高采集效率,可以使用一个单独的服务,每隔一段时间,检测一次网站和栏目的情况。一是检测网站、栏目是否能正常访问;二要检测配置的栏目信息正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
10万个网站,配置完栏目以后,采集的入口URL应该会达到百万级别。采集器如何高效的获取这些入口URL进行采集呢?
如果把这些URL放到数据库中,不管是MySQL,还是Oracle,采集器获取采集任务这一操作,都会浪费很多时间,大大降低采集效率。
如何解决这个问题呢?内存数据库便是首选,如Redis、 Mongo DB 等。一般采集用Redis来做缓存。所以,可以在配置栏目的同时,把栏目信息同步到Redis中,作为采集任务缓存队列。

四、网站如何采集?
就像是你想达到年薪百万,最大概率是要去华为、阿里、腾讯这种一线大厂,而且还需要到一定的级别才行。这条路注定不易。
同样,如果需要采集百万级别的列表URL,常规的方法也一定是无法实现。
必须使用分布式+多进程+多线程的方式。同时,还需要结合内存数据库Redis等做缓存,已实现高效获取任务,以及对采集信息进行排重;

同时,信息的解析,如发布时间、正文等,也必须使用算法来处理。比如现在比较火的GNE,
有些属性,可以在列表采集时获取的,就尽量不要放到和正文一起进行解析。比如:标题。一般情况下,从列表中获取到的,标题的准确度,要远大于算法从信息html源码中解析的。
同时,如果有一些特殊网站、或者一些特殊需求,我们再采用定制开发的方式进行处理即可。
五、统一数据存储接口
为了保持采集的及时性,10万个网站的采集,可能需要十几二十台服务器。同时,每台服务器上又部署N个采集器,再加上一些定制开发的脚本,整体采集器的数量将会达到上百个。
如果每个采集器/定制脚本,都自行开发一套自己的数据保存接口,则开发、调试就会浪费不少时间。而且后续的运维,也将是一件非糟心的事情。尤其是业务有所变化,需要调整时。所以,统一数据存储接口还是很有必要的。
由于数据存储接口统一,当我们需要相对数据做一些特殊处理时,比如:清洗、矫正等,就不用再去修改每个采集存储部分,只需要修改一下接口,重新部署即可。
快速、方便、快捷。
六、数据及采集监控
10万个网站的采集覆盖度,每天的数据量绝对在200万以上。由于数据解析的算法无论多精确,总是不能达到100%(能达到90%就非常不错了)。所以,数据解析一定会存在异常情况。比如:发布时间大于当前时间、正文中包含相关新闻信息等等。
但是,由于我们统一了数据存储接口,此时就可以在接口处,进行统一的数据质量校验。以便根据异常情况,来优化采集器及定制脚本。
同时,还可以统计每个网站或栏目的数据采集情况。以便能够及时地判断,当前采集的网站/栏目信源是否正常,以便保证始终有10万个有效的采集网站。
七、数据存储
由于每天采集的数据量较大,普通的数据库(如:mysql、Oracle等)已经无法胜任。即使像Mongo DB这样的NoSql数据库,也已经不再适用。此时,ES、Solr等分布式索引是目前最好的选择。
至于是否上Hadoop、HBase等大数据平台,那就看具体情况了。在预算不多的情况下,可以先搭建分布式索引集群,大数据平台可以后续考虑。
为了保证查询的响应速度,分布式索引中尽量不要保存正文的信息。像标题、发布时间、URL等可以保存,这样在显示列表数据时可以减少二次查询。
在没有上大数据平台期间,可以把正文以固定的数据标准,保存到txt等文件系统中。后续上大数据平台后,再转存到HBASE中即可。
八、自动化运维
由于服务器、采集器,以及定制脚本较多,单纯的靠人工进行部署、启动、更新、运行情况监控等,已经显得非常的繁琐,且容易出现人为失误。
所以,必须有一套自动化运维系统,能够实现对采集器/脚本进行部署、启动、关闭、运行等,以便能够在出现变动时快速的响应。
“比如有10万个网站需要采集,你有什么方法快速的获取到数据?”,如果你能回答出这些,拿到一个不错的offer应该没什么悬念。
最后,愿正在找工作的各位朋友,都能收获满意的offer,找到一个不错的平台。


