






互联网是由一个个站点和网络设备组成的大网,我们通过浏览器访问站点,站点把HTML、JS、CSS代码返回给浏览器,这些代码经过浏览器解析、渲染,将丰富多彩的网页呈现我们眼前。
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物(数据)。爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序。
如今,人类社会已经进入了大数据时代,如何高效的获取数据,已经成了各个互联网公司的技术研发重点,掌握爬虫技术已经成为了大数据公司技术人员不可或缺的一项技能。
开发爬虫使用的语言,一般有C++、Java或者Python等,这些都是面向对象的编程语言。其中C++和Java都是强类型语言,而Python是一种弱类型语言。那么这三类语言都是有什么优缺点呢?请看下面描述:
1)JAVA Java的语法比较规则,采用严格的面向对象编程方法,同时有很多大型的开发框架,比较适合企业级应用。Java的学习曲线较长,不仅要学习语言相关的特性,还要面向对象的软件构造方法,在此之后要学习一些框架的使用方法。 (1)用途:Android & IOS 应用开发,视频游戏开发,桌面GUIs(即图形用户页面),软件开发,架构等。 (2)优势:面向对象开源、跨平台、市场需求旺盛;Android开发的基石, 是Web开发的主流语言; (3)缺点:占用大量的内存,启动时间较长,不直接支持硬件级别的处理
2)Python python是动态形的灵活的解释性语言,从软件开发到Web开发,Python都有在被使用。 因为它是解释性脚本语言,适合轻量级开发。Python是比较好学的语言。 (1)用途:爬虫,Web开发,视频游戏开发,桌面GUIs(即图形用户页面),软件开发,架构等。 (2)优势:动态解释型、拥有强大的开源类库、开发效率高、开源,灵活,入门低易上手 (3)缺点:运行速度低于编译型语言,在移动计算领域乏力
3)C++ C++更接近于底层,方便直接操作内存。C++不仅拥有计算机高效运行的实用性特征,同时还致力于提高大规模程序的编程质量与程序设计语言的问题描述能力。C++运行效率较高,同时能够比较容易地建立大型软件,适合对效率要求高的软件。C++的内容非常复杂,同时语言经过了几十年的演化,所以学习起来难度较大,开发效率较低。 1)用途: 机器学习中的神经网络、大型游戏编程、后台服务、桌面软件等 2)优势:运行效率高、安全、面向对象、简洁、可重用性好等 3)缺点:没有垃圾回收机制,可能引起内存设漏; 学习难度大,开发效率相对较低; 通过在GitHub上搜索”爬虫”,我们可以发现,目前市面上的开源爬虫项目,Python占百分八十的份额。

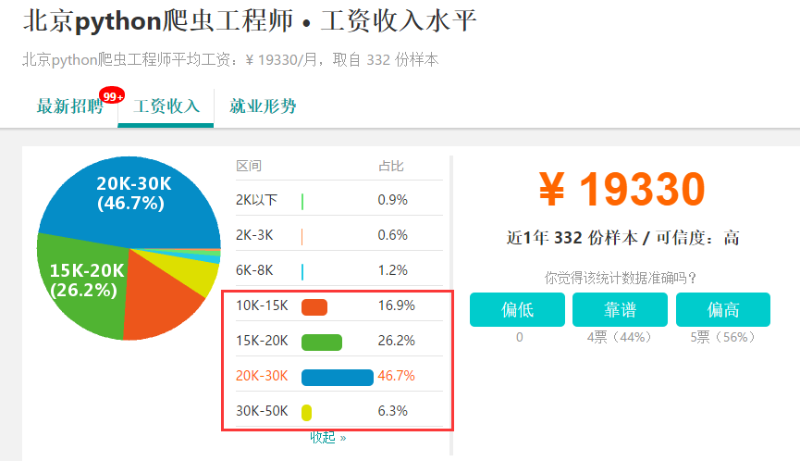
而且目前市面上,具有两年以上Python爬虫经验的工程师,其工资普遍高于Java和C++爬虫工程师。
所以,Python才是开发爬虫不二的选择。那么一个初学者掌握哪些知识,就可以使用Python开发爬虫呢?
1.网络 urllib -网络库(stdlib)。 requests -网络库。 grab – 网络库(基于pycurl)。 pycurl – 网络库(绑定libcurl)。 urllib3 – Python HTTP库,安全连接池、支持文件post、可用性高。 httplib2 – 网络库。 RoboBrowser – 一个简单的、极具Python风格的Python库,无需独立的浏览器即可浏览网页。 MechanicalSoup -一个与网站自动交互Python库。 mechanize -有状态、可编程的Web浏览库。 socket – 底层网络接口(stdlib)。
2.HTML/XML解析器 lxml – C语言编写高效HTML/ XML处理库。支持XPath。 cssselect – 解析DOM树和CSS选择器。 pyquery – 解析DOM树和jQuery选择器。 BeautifulSoup – 低效HTML/ XML处理库,纯Python实现。 html5lib – 根据WHATWG规范生成HTML/ XML文档的DOM。该规范被用在现在所有的浏览器上。 feedparser – 解析RSS/ATOM feeds。 MarkupSafe – 为XML/HTML/XHTML提供了安全转义的字符串。
3.浏览器自动化与仿真 selenium – 自动化真正的浏览器(Chrome浏览器,火狐浏览器,Opera浏览器,IE浏览器)。 Ghost.py – 对PyQt的webkit的封装(需要PyQT)。 Spynner – 对PyQt的webkit的封装(需要PyQT)。 Splinter – 通用API浏览器模拟器(selenium web驱动,Django客户端,Zope)。
4.多重处理 threading – Python标准库的线程运行。对于I/O密集型任务很有效。对于CPU绑定的任务没用,因为python GIL。 multiprocessing – 标准的Python库运行多进程。 celery – 基于分布式消息传递的异步任务队列/作业队列。 concurrent-futures – concurrent-futures 模块为调用异步执行提供了一个高层次的接口。
5.异步网络编程库 asyncio – (在Python 3.4 +版本以上的 Python标准库)异步I/O,时间循环,协同程序和任务。 gevent – 一个使用greenlet 的基于协程的Python网络库。
6.网页内容提取 HTML页面的文本和元数据 newspaper – 用Python进行新闻提取、文章提取和内容策展。 html2text – 将HTML转为Markdown格式文本。 python-goose – HTML内容/文章提取器。 lassie – 人性化的网页内容检索工具
了解了以上的知识点以后,我们获取网络数据的方式有哪些呢?
方式1:浏览器提交请求--->下载网页代码--->解析成页面
方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
爬虫要做的就是方式2。
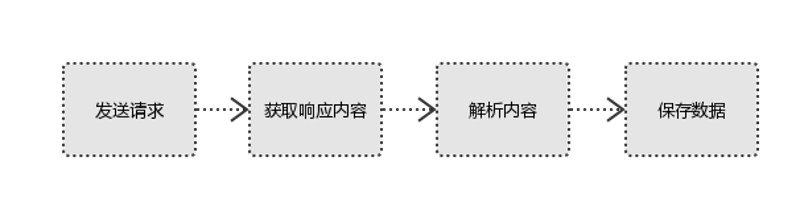
1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
目前上市面上开源爬虫项目主要有一下八个:
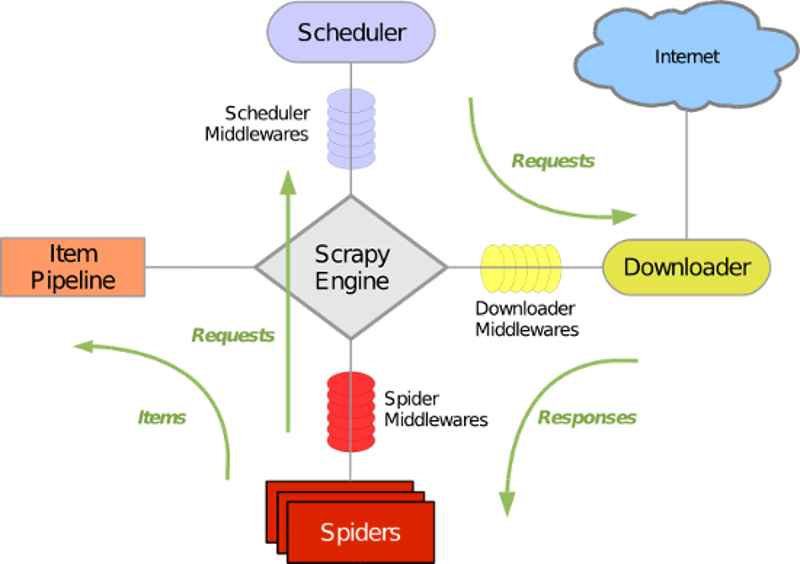
1.Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。
项目地址:https://scrapy.org/
2.PySpider pyspider 是一个用python实现的功能强大的网络爬虫系统,能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储,还能定时设置任务与任务优先级等。 项目地址:https://github.com/binux/pyspider
3.Crawley Crawley可以高速爬取对应网站的内容,支持关系和非关系数据库,数据可以导出为JSON、XML等。
项目地址:http://project.crawley-cloud.com/
4.Portia Portia是一个开源可视化爬虫工具,可让您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。 项目地址:https://github.com/scrapinghub/portia
5.Newspaper Newspaper可以用来提取新闻、文章和内容分析。使用多线程,支持10多种语言等。 项目地址:https://github.com/codelucas/newspaper
6.Beautiful Soup Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。 项目地址:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
7.Grab Grab是一个用于构建Web刮板的Python框架。借助Grab,您可以构建各种复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网络请求和处理接收到的内容,例如与HTML文档的DOM树进行交互。 项目地址:http://docs.grablib.org/en/latest/#grab-spider-user-manual
8.Cola Cola是一个分布式的爬虫框架,对于用户来说,只需编写几个特定的函数,而无需关注分布式运行的细节。任务会自动分配到多台机器上,整个过程对用户是透明的。 项目地址:https://github.com/chineking/cola

