






3月12日下午,国务院联防联控机制召开新闻发布会,国家卫健委新闻发言人表示,总体上我国本轮疫情流行高峰已经过去,新增发病数在持续下降,疫情总体保持在较低水平。
“高峰已过”,意味着这场蔓延全国的新冠肺炎疫情整体上得到有效控制,这对疫情防控,民众工作与生活,企业复工复产等各方面都透露出积极信号。
上班的第一天,大BOSS为了蹭热点,宣传自己的产品说:小王,把微信公众号中发布的与疫情相关的数据都给我搜集过来,给报告组做个分析报告发布出去。这时,你该如何获取这些数据呢?
那么公众号**采集有哪些流程**呢?
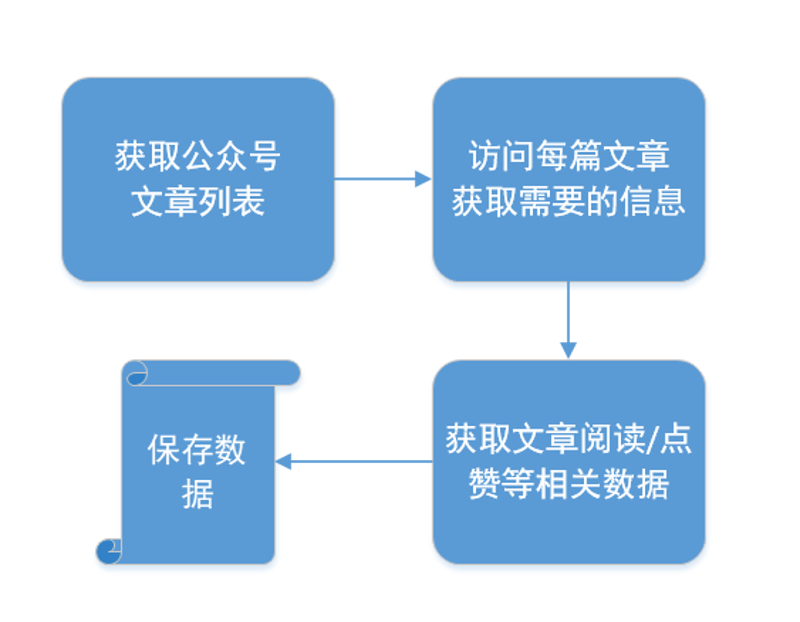
那我们首先分析一下公众号的采集方式有哪些?
1:基于搜狗微信
2019年4月份以前,能够查询公众号最近发布的十条文章。但是,四月份时,历史信息的暂时下线了。但是关键词搜索结果中可以过滤某个公众号的文章,同时可以搜索某一时间段内容的文章。

2019年八月初,搜狗把公众号过滤和时间过滤,也给屏蔽了,搜狗微信搜索对于采集来说,彻底失去了意义。因为,搜索结果没有办法按时间排序,列表中绝大部分都是历史信息,有的甚至是几年前的数据,而且在不登录的情况下只能查看10页,即使登陆了,也只能查看100页。最新信息能有几条?
2:基于微信网页版
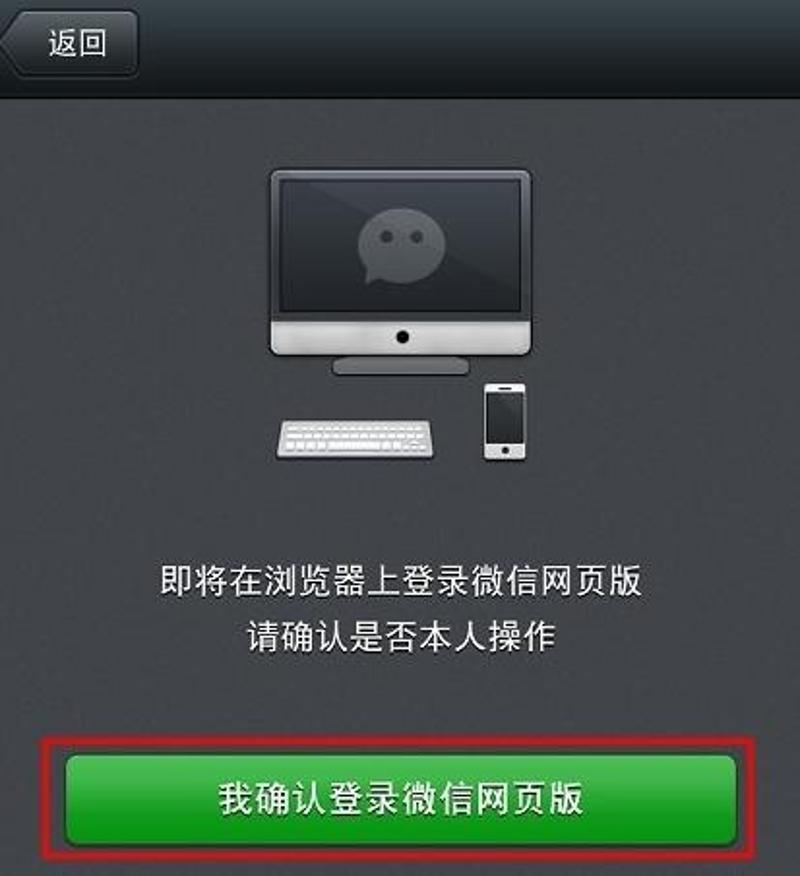
基于微信网页版的采集,一般情况下就是使用itchat插件进行脚本的开发,从而获取微信的相关数据,但是该方式对微信号有一定的限制,必须是老号(至少是2017年10月份以前注册的),且能够登陆网页版微信。
同时,也要注意封号的情况,我做测试时,就导致自己使用的微信号被封了。苦逼....
由于现在使用微信网页版的人很少,网页版有可能会停止更新,更甚者停止服务。所以,也存在极大的风险。
3:基于AnyProxy代理
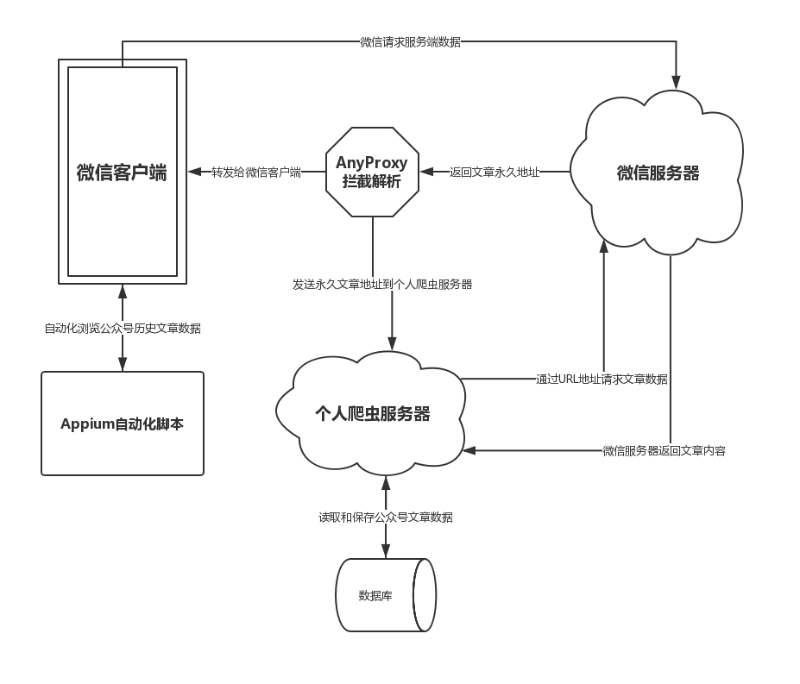
AnyProxy是一个开放式的HTTP代理服务器,官方文档可以在GitHub上找到,它具有以下特性:
基于Node.js,开放二次开发能力,允许自定义请求处理逻辑
支持Https的解析
提供[GUI](http://www.blog2019.net/tag/GUI?tagId=22)界面,用以观察请求
要使用这种方式,必须有一台联网的电脑,该电脑上安装好AnyProxy需要的所有环境,配置好参数启动AnyProxy代理服务器。微信所在的手机通过WiFi连接到该电脑上即可。
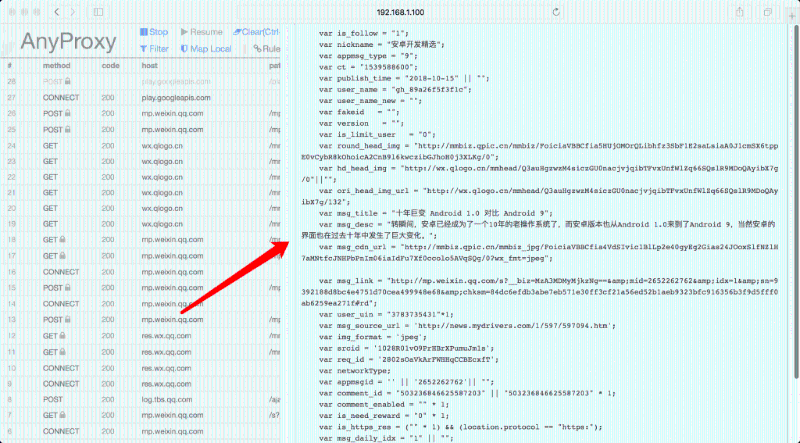
这种方式可以采集公众号自动推送的文章,如果要采集某个公众号的历史文章,那就需要到公众号的历史页,人工向下滑动加载数据。如果是大批量公众号的历史文章,那就需要写个脚本自动滑动了。
4:基于XPosed插件

这种方式就需要我们Xposed Hook微信了,通过这种方式,我们可以实时的接收公众号推送的数据,并能将其发送到对应的接口进行保存。如果你要大批量的采集公众号,比如几千、几万或者几十万,那这种方式是目前来说最稳定、最高效、最容易运维等方式。
但是这种方式有一个最大的缺点,前期投入较大。一个微信号只能关注999个公众号,如果你要关注一万一个公众号,就需要10部手机,而且手机还不能是三五百的便宜货,否则运维会很麻烦。所以采集一万个公众号的硬件投入大概如下: 1200(10部手机)+500(10个过了养号期的微信号)+120(10个USB口的转换头)+50(十卡位的支架用于放手机)+120(无线路由)=1990元;
这是最基本的投入,如果数据量更大的话,硬件的投入大致可以按上述费用乘以比例,然后总费用*85%来计算。这种方式在运维中需要注意的是:
网络必须要稳定;
每天至少需要查看3~5次,看微信是否卡死
定期清理手机垃圾
其中网络是最重要的因素,如果网络不好,很容易造成微信加载数据时卡死。如果是大批量采集时,所有的手机最好不要连接同一个WiFi(对外IP不能是一个),否则容易导致微信号异常。
为了保证采集能够稳定,同时需要预留一些微信号,为了防止一些使用的号异常时,马上有号能替补上。
5:基于微信PC端

这种方式,可以用于采集公众号微信,也可以用于关键词搜索,不过相对来说,作为关键词搜索的一种采集方式应该是最合适的。比较公众号有三几千万,我们不可能全部监测到,为了能够较快的获取我们相关的数据,使用重点公众号实时监测+关键词搜索的方式应该是最合适的。
基于微信PC端的关键词搜索,先前写过一篇文章,大家可以去看看。
现在你找到大BOSS交给你的任务,如何去解决了吗?哈哈.....

