×
请登录
账号
密码
登录 Use it
博客
新媒体
活动
方案
爬虫
热点
标签
登录
注册
博主QQ
博主QQ:
博主微信
博主微信:
博主公号
博主公众号:
回到顶部
标签: 采集架构 共 1 个结果.
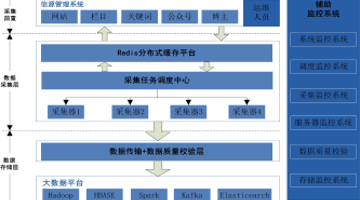
基于大数据平台的互联网数据采集平台基本架构
互联网的飞速发展将社会带入数据高度发达且公开的信息时代,数据对于企业经营、政府决策及社会动态分析等具有极其重要的作用,而如何大规模、快速采集数据成为技术焦点。 网络爬虫是按照一定规则自动游走爬取互联网文本网页的程序或者脚本。文本数据大多嵌套于网页...
十点数据
1年前
7002
1
1
博主公众号:
博主微信:
热门文章
1.
爬虫系列之Pyppeteer:比selenium更高效的爬虫界的新神器
2.
LayUi的Table表格defaultToolbar工具栏的显示与隐藏(权限控制)
3.
Spring Boot 踩坑系列之Error resolving template
4.
LayUi的动态表格table中设置下拉框Select编辑器
5.
基于JavaScript的流程图
6.
一个不错的验证码打码平台
最新发布
1.
selenium突然如下报错时,selenium退回4.9.0即可
2.
html.unescape与HTMLParser().unescape使用区别
3.
AttributeError: module 'networkx' has no attribute 'from_numpy_m
4.
Python3安装textrank4zh实现分词关键词提取及摘要生成报错:AttributeError: module ‘networkx’ has no attribute ‘from_numpy_matrix’
5.
阿里云域名解析到非80端口
6.
新版知乎x-zse-96参数101_3_3.0版分析
最新评论
和游戏外挂类似
基于内存,让我想到了易语言,游戏内存挂的开发,类似的技术吗?
赞,感谢分享
目前自己在用的就是这种方式,几万个关键词,每天采集量有小一百万的量。目前时间范围限制在一天
感谢分享
充值完但没有积分